消費者の心理的側面からのアプローチは重要性を増してきております。そして世の中の仕組みや人々の志向が複雑化・多様化する今は、より洗練された分析モデルが必要になっております。
構造方程式モデリング(SEM)は仮説を元に複雑に絡んだ因果関係を分析者がモデリング(構造方程式を構築)して値を推定、分析をかける手法です。これは複雑な原理・現象を因果モデルとして表し単純化することを目的として、分析者がモデルを柔軟に設定できることを意味します。 SEMはモデルを構築し、推定値を求める段階で変数の分散や共分散の情報を用いることから"共分散構造分析(CSA)"とも呼ばれております。
モデル中には「潜在変数」という仮想的な構成概念を置くことができ、集約化することによって、現状に沿った解釈可能な結果を導くことができます。これは従来の多変量解析で言うところの「因子」に相当します。 SEMではこれを更に拡張し、因子間の因果関係をも設定して分析することができます。このようにSEMは従来の回帰分析や因子分析をはじめ、様々な多変量解析の上位概念モデルに相当します。
また、多彩な適合度指標により、モデル全体が適切に表現さているか量的に判断できるようになります。


共分散構造分析(SEM)
− 作り上げた仮説をモデルとして捉えて分析・検証したい
− 複雑な原理・現象を論理的、合理的に解釈したい
− モデルを利用してセグメンテーションなどをしたい
− これまでの古典的手法だけでは得られなかった量的な結果がほしい
このようなニーズには「構造方程式 モデリング(SEM) 〜共分散構造分析〜」が適しています。
"モノ"が売れない時代・・
e.g.製品特性と消費者の購買意欲との関係を考える
SEMの仕組みをご理解いただく上で基本的な事項をこの"多重指標モデル"と呼ばれる事例に基づいて考えてみます。 一般に製品特性を決定する要素として、性能、価格、納期(が早い、あるいは適切なタイミングで引渡される)などが考えられます。一方、消費者の購買意欲は趣味・嗜好、広告など外部からの刺激、本人の習慣(Habit)、必要性、あるいは頻度などから促されるものと考えられます。これらの要素を調査票の中に質問として組み込み、対象者から回答を募ります。(測定する) しかし、せっかく苦労して集めた情報も、これらの関係を愚直にモデル化しようとすると様々な要因が複雑に絡んでいて、できあがったものは結局よくわからないものになってしまうおそれがあります。
そこで、以下のパス図のようにモデルの中に"製品特性"と"購買意欲"という名の「潜在変数」とした概念の集約版を置いて、関係を整理することを考えます。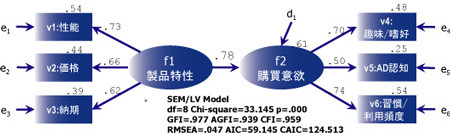
製品特性は性能、価格、納期を測定する構成概念と捉えることができます。同様に購買意欲もそれぞれの指標(調査から観測される変数)を測定する構成概念と捉えることができます。この部分のみに着目すると、従来の多変量解析で言うところの"因子分析"と捉えることができます。 そして、製品特性と購買意欲という構成概念同士はそれぞれ、原因系と結果系のような関係で表現できると考えられます。この部分は"回帰分析"と捉えることができます。 今回の最も知りたいことが構成概念として表現され、かつその関係を整理することで、モデル全体がすっきりと見通しが良くなってきました。分析者が柔軟にモデル設定できるところも大きな特徴です。
このようにSEMの考え方の中には、これまでの多変量解析の仕組みが包含されており、かつモデル全体として評価できるので、より洗練された分析方法であると言えます。
そこで、以下のパス図のようにモデルの中に"製品特性"と"購買意欲"という名の「潜在変数」とした概念の集約版を置いて、関係を整理することを考えます。
製品特性は性能、価格、納期を測定する構成概念と捉えることができます。同様に購買意欲もそれぞれの指標(調査から観測される変数)を測定する構成概念と捉えることができます。この部分のみに着目すると、従来の多変量解析で言うところの"因子分析"と捉えることができます。 そして、製品特性と購買意欲という構成概念同士はそれぞれ、原因系と結果系のような関係で表現できると考えられます。この部分は"回帰分析"と捉えることができます。 今回の最も知りたいことが構成概念として表現され、かつその関係を整理することで、モデル全体がすっきりと見通しが良くなってきました。分析者が柔軟にモデル設定できるところも大きな特徴です。
このようにSEMの考え方の中には、これまでの多変量解析の仕組みが包含されており、かつモデル全体として評価できるので、より洗練された分析方法であると言えます。
モデルの解釈・分析
本仮説モデルとこの解釈はあくまで分析手法のイメージを掴んでいただくためのもので、実際の分析モデルではありません。本事例の推定値に関する一切の責任と保証は負いかねます。
◆製品特性が高いと購買意欲は上がることが示唆される。
(相関係数で0.78相当)
◆製品特性は"性能"を決定付ける大きな要因であると考えられる。
(因子負荷量0.73,決定係数0.54)
◆モデル全体sの当てはまり具合はおおむね良好であった。このモデルで全体の
状況がよく説明できていると考えられる。
SEMの応用例
SEMの考え方を応用させた様々な分析方法があります。
SEMは近年、理論はもとよりコンピュータの発展と共に複雑な計算が可能となり、ソフトウェアも急激な進化を遂げており、ますます目が離せない分析手法と言えます。
SEMによりお客様の抱える様々な問題に対する量的な判断を示唆できる可能性があります。
お気軽にご相談下さい。
Solution 1 「多母集団の同時分析」
例えば「性別」(男性|女性)、「地域」(東京|大阪)など、異なる集団間を比較分析する際、「潜在変数」はそもそも分析者が勝手に設定した構成概念なので単位がなく、一般に比較は困難です。 多母集団の同時分析では推定値を複数の集団で同時に算出するので、集団間の比較解釈が容易になります。
Solution 2 「潜在構造分析」
企業戦略において、特定の顧客にターゲットを絞った「セグメンテーション」は重要性を増してきております。そのセグメントの特性を知ることで、効果的な製品投入や顧客からの信頼を獲得できる可能性を秘めております。 しかし、その観点や切り口は実際のところ、どこをどうしたら良いかわからない場合が少なくありません。
潜在構造分析は背後にカテゴリカルな分布(潜在変数が名義変数)を想定したモデルを用いて分析するので、どのような集団がどのくらいの割合で構成されているのかを量的に示唆してくれます。 従来の多変量解析「判別分析」の潜在変数版のような分析が可能となります。(従来の手法は線形判別式やマハラノビス汎距離などを用いて、判別すべく切り口は既知の観測変数でしたが、その切り口自体を潜在変数とし、背後に潜在構造を規定してそこからアプローチをかける) また、SEMならではの利点で、いくつかセグメントした分析モデルの中から適合度指標や情報量規準を参考にして、どれが当てはまりが良いかの比較検討もできるので、より有益な結果をもたらすことが期待できます。
潜在構造分析は背後にカテゴリカルな分布(潜在変数が名義変数)を想定したモデルを用いて分析するので、どのような集団がどのくらいの割合で構成されているのかを量的に示唆してくれます。 従来の多変量解析「判別分析」の潜在変数版のような分析が可能となります。(従来の手法は線形判別式やマハラノビス汎距離などを用いて、判別すべく切り口は既知の観測変数でしたが、その切り口自体を潜在変数とし、背後に潜在構造を規定してそこからアプローチをかける) また、SEMならではの利点で、いくつかセグメントした分析モデルの中から適合度指標や情報量規準を参考にして、どれが当てはまりが良いかの比較検討もできるので、より有益な結果をもたらすことが期待できます。
Solution 3 「カテゴリカル因子分析」
アンケート調査にありがちな「はい」or「いいえ」のように回答選択肢が2択(2値データ)などの観測変数に対してSEMなどの多変量解析をかける場合、通常の連続変数のように扱うと推定値は真値からはかけ離れたものとなってしまい、分析結果としては望ましくありません。
カテゴリカル因子分析はこのようなカテゴリーデータに対して有効な分析方法です。この考え方はIRTにも応用化されております。
カテゴリカル因子分析はこのようなカテゴリーデータに対して有効な分析方法です。この考え方はIRTにも応用化されております。
Solution 4 「コレスポンデンス分析」
コレスポンデンス分析は2つのカテゴリカル変数の相互関係を解析することが主目的で、例えば「ブランド x エクイティ」などのマッピングによく使われます。この手法はフランスから端を発し、日本では「対応分析」と呼ばれております。
一方、日本においてもカテゴリカル変数の分析手法は「林の数量化理論」という独自の進化を遂げ、特に「数量化理論III類」は数理的にコレスポンデンス分析と同義であることが知られています。
SEMでも「MIMICモデル」、「正準相関分析」の応用として、これらのモデルを表現することができます。これまでの分析手法では得られた値に対して有意性の検定ができませんでした。(∵コレスポンデンス分析の数理はこれまで統計学というよりはむしろ、特異値問題を解くことが主眼であり、線形代数からのアプローチが主流であったため)
SEMを利用することにより標準誤差を使えるので検定がかけられること、並びにSEMの枠組みで実行するため、様々なモデル指標が参照でき、モデル間の比較が容易になるメリットが考えられます。
これにより、表現豊かな解釈が期待できます。
一方、日本においてもカテゴリカル変数の分析手法は「林の数量化理論」という独自の進化を遂げ、特に「数量化理論III類」は数理的にコレスポンデンス分析と同義であることが知られています。
SEMでも「MIMICモデル」、「正準相関分析」の応用として、これらのモデルを表現することができます。これまでの分析手法では得られた値に対して有意性の検定ができませんでした。(∵コレスポンデンス分析の数理はこれまで統計学というよりはむしろ、特異値問題を解くことが主眼であり、線形代数からのアプローチが主流であったため)
SEMを利用することにより標準誤差を使えるので検定がかけられること、並びにSEMの枠組みで実行するため、様々なモデル指標が参照でき、モデル間の比較が容易になるメリットが考えられます。
これにより、表現豊かな解釈が期待できます。
コレスポンデンス分析
ページ上へ