怴惢昳奐敪偵偍偄偰丄捈慜偺挷嵏偵傛傞偲崅偄峸擖堄岦偑帵偝傟偨偺偵丄偄偞敪攧偟偰傒傞偲巚偄偺傎偐攧忋偑怢傃擸傫偩偲偄偆嬯偄偛宱尡傪偝傟偨偙偲偼側偄偱偟傚偆偐? 尨場偼偄傠偄傠峫偊傜傟傑偡偑丄傕偟偐偟偨傜偦傟偼丄僞乕僎僢僩偲偟偨屭媞偺杮幙揑側乽峸攦椡乿偑懌傝側偄偺偐傕抦傟傑偣傫丅
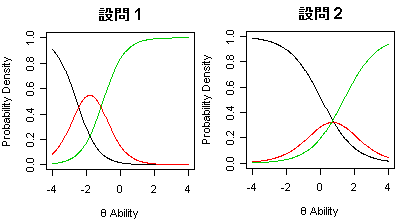
堦斒偵峸擖堄岦傪丒蕮I挷嵏偵偐偗傞偲偒丄 [ 旕忢偵攦偄偨偄 | <--> | 慡慠攦偄偨偔側偄 ] 側偳偺5抜奒昡壙偺傛偆側慖戰巿傪懳徾幰偵夞摎偝偣傞僷僞乕儞偑懡偄偲巚偄傑偡丅 偟偐偟丄偙偙偱A偝傫偺夞摎偟偨"旕忢偵攦偄偨偄"偲B偝傫偺夞摎偟偨"旕忢偵攦偄偨偄"偼杮幙揑偵摨偠偲尵偊傞偺偱偟傚偆偐? 慜弎偺傛偆側捠忢偺幙栤宍幃偺挷嵏偱偼丄偦偺堘偄傪尒弌偡偙偲偼偱偒傑偣傫丅
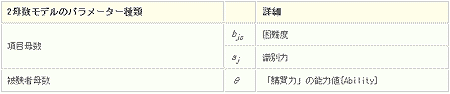
崁栚斀墳棟榑(IRT)偼尦棃丄僥僗僩棟榑偺榞慻傒偱愢柧偝傟丄帋尡栤戣側偳傪峔抸偡傞偨傔偺棟榑偱偡丅椺偊偽丄TOEIC偺傛偆側帋尡偱860揰埲忋傪扏偒弌偡恖偼丄偄偮丄偳偙偱丄扤偑庴尡偟傛偆偑"廫暘側塸岅僐儈儏僯働乕僔儑儞擻椡傪桳偡傞恖"偲偄偆揤壓柍揋偺徧崋偑梌偊傜傟傑偡丅 偙傟傪墳梡偟偰丄懳徾偲側傞惢昳偵懳偟偰挷嵏傪偐偗傞偲偄偆傛傝偼傓偟傠丄偄傢偽愨懳揑丒摑堦揑側婎弨丒広搙傪嶌偭偰偟傑偄丄僞乕僎僢僩屭媞偺乽峸攦椡乿側傞擻椡抣傪應傠偆偲偄偆峫偊曽偱偡丅
惢昳奐敪偺弶婜抜奒偱丄偙偺傛偆偵婎慴揑側挷嵏傪慻傒崬傓偙偲偱儉僟偺柍偄搳帒丄崌棟揑側奐敪偑悑峴偝傟傞偙偲偑婜懸偱偒丄嬌傔偰桳塿偱偁傞偲巚傢傟傑偡丅
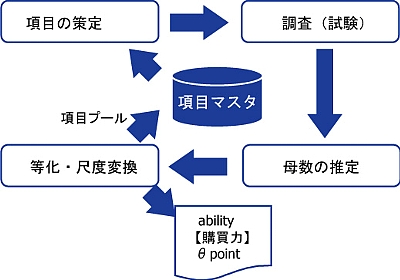
IRT偼愨懳揑丒摑堦揑婎弨傪嶌惉偡傞偙偲傪戞1偺栚揑偲偟傑偡丅偦偺偨傔偵偼挷嵏愝栤崁栚偑偳偺傛偆側惈幙傪帩偭偰偄傞偺偐嬦枴偡傞昁梫偑偁傝傑偡丅偦偺偨傔儌僨儖曣悢悇掕偐傜摍壔傗広搙曄姺偲尵偭偨庤弴傪傆傓娫偵丄愝栤崁栚傪嬦枴偡傞偙偲偲"崁栚儅僗僞"偺懚嵼偑偐偐偣傑偣傫丅崁栚儅僗僞偲偼丄愝栤偺悧宍偲偦傟偵晅悘偡傞曣悢偺抣傪拁愊偟偰偍偔応強偱偡丅偙偺傛偆偵IRT偺挿強傪惗偐偡偨傔偵丄偔傝偐偊偟挷嵏傪宲懕偡傞丒眰苽獖虠v偱偡丅